
¿Qué es Docker? ¿Para qué se utiliza?
- Laure

- 11 sept 2021
- 7 min de lectura
Actualizado: 20 sept 2021

Como ya sabrás, existen varios tipos de virtualización, uno de ellos es la virtualización a nivel de sistema operativo, y uno de los proyectos que más destaca en este sentido es Docker, junto con otros proyectos open-source como OpenVZ, LXC/LXD, Linux-VServer, etc..., o el software propietario Virtuozzo. Si conoces este mundo, ya sabrás del proyecto cuyo logo es una ballena, y sobre todo habrás notado como en éstos últimos años su presencia en los medios e interés ha ido aumentando exponencialmente.
Solomon Hykes estaba tratando de encontrar una solución para que los programadores proporcionen un código que se ejecute igual tanto en su entorno de desarrollo como en el de producción y esto resultó en la creación de Docker Container.
Y es que estas nuevas tecnologías son el presente y el futuro, sobre todo con el brutal crecimiento de los servicios en la nube. Docker, entre otros muchos proyectos de código abierto y libres, son los que están permitiendo esa expansión y grandes posibilidades que requerimos de la nube. Pero ¿Qué es Docker? ¿Qué es un contenedor? ¿Cómo funciona?
Historia
Allá por 2013 Docker empezó a ganar popularidad permitiendo a los desarrolladores crear, ejecutar y escalar rápidamente sus aplicaciones creando contenedores. Parte de su éxito se debe a ser Open Source y al apoyo de compañías como IBM, Microsoft, RedHat o Google. Docker en apenas dos años había sido capaz de convertir una tecnología nicho en una herramienta fundamental al alcance de todos gracias a su mayor facilidad de uso.
Su evolución ha sido imparable, representando actualmente uno de los mecanismos comunes para desplegar software en cualquier servidor por medio de contenedores software. Tanto Docker como Kubernetes, conocidos por ser uno de los más populares gestores de contenedores de software, se han convertido con méritos propios en los estándares de facto de la industria.
Google, Microsoft, Amazon, Oracle, WMware, IBM, RedHat están apostando fuertemente por estas tecnologías, ofreciendo todo tipo de servicios a los desarrolladores en la nube. Hoy por hoy todo va encaminado a ser dockerizado, como popularmente se refiere en castellano al hecho de empaquetar una aplicación software para ser distribuida y ejecutada mediante el uso de esos contenedores software.
Entendemos que no todo el mundo está familiarizado con el término, pero si eres desarrollador de software debes empezar a aprender más sobre ello, ya que ha sido la auténtica revolución en años de la industria del software. Gracias de él, los desarrolladores hemos podido independizarnos en cierta medida de los sysadmin y hemos abrazado el concepto de devops más abiertamente.
¿Qué son los contenedores de software?
Para explicar qué son los contenedores software vamos a bajar al nivel más simple de abstracción. Buscando alguna analogía con el mundo real podemos hablar de esos containers que vemos siendo transportados en barco de un sitio a otro. No nos importa su contenido sino su forma modular para ser almacenados y transportados de un sitio a otro como cajas.

Algo parecido ocurre con los contenedores software. Dentro de ellos podemos alojar todas las dependencias que nuestra aplicación necesite para ser ejecutada: empezando por el propio código, las librerías del sistema, el entorno de ejecución o cualquier tipo de configuración. Desde fuera del contenedor no necesitamos mucho más. Dentro están aislados para ser ejecutados en cualquier lugar.
Los contenedores son la solución al problema habitual, por ejemplo, de moverse entre entornos de desarrollo como puede ser una máquina local o en un entorno real de producción. Podemos probar de forma segura una aplicación sin preocuparnos de que nuestro código se comporte de forma distinta. Esto es debido a que, como nos referíamos antes, todo lo que necesitamos está dentro de ese contenedor.
Solomon Hykes, creador de Docker, lo explicaba del siguiente modo: “utilizando contenedores para ejecutar tu código solventamos el típico quebradero de cabeza de que estés usando una versión de Python 2.7 diferente en local o en el entorno de pruebas pero en producción la versión sea totalmente distinta como Python 3 u otras dependencias propia del entorno de ejecución, incluso el sistema operativo. Todo lo que necesitas está dentro del propio contenedor y es invariable”.

En definitiva, los contenedores representan un mecanismo de empaquetado lógico donde las aplicaciones tienen todo lo que necesitan para ejecutarse. Describiéndolo en un pequeño archivo de configuración. Con la ventaja de poder ser versionado, reutilizado y replicado fácilmente por otros desarrolladores o por los administradores de sistemas que tenga que escalar esa aplicaciones sin necesidad de conocer internamente cómo funciona nuestra aplicación. El fichero de Docker bastará para adecuar el entorno de ejecución y configurar el servidor dónde va a ser escalado. A partir de ese fichero se puede generar una imagen que puede ser desplegada en un servidor en segundos.
Contenedores versus Virtualización
Una de las principales dudas es en qué se diferencia entonces un contenedor software y una máquina virtual. De hecho, este concepto es mucho más anterior que el de los propios contenedores.
Gracias a la virtualización somos capaces, usando un mismo ordenador, de tener distintas máquinas virtuales con su propio sistema operativo invitado, Linux o Windows. Todo ello ejecutándose en un sistema operativo anfitrión y con acceso virtualizado al hardware.
La virtualización es una práctica habitual en servidores para alojar diferentes aplicaciones o en nuestro propio entorno de trabajo para ejecutar distintos sistemas operativos, por ejemplo. Muchos alojamientos de hosting tradicionales se han basado en crear máquinas virtuales limitadas sobre el mismo servidor para alojar nuestros servidores web de forma aislada, siendo compartido por una decena de clientes.

En contraposición a las máquinas virtuales, los contenedores se ejecutan sobre el mismo sistema operativo anfitrión de forma aislada también, pero sin necesitar un sistema operativo propio, ya que comparten el mismo Kernel, lo que los hace mucho más ligeros. De donde sacamos 3 máquinas virtuales probablemente podemos multiplicarlo por un gran número de contenedores software.
Un contenedor de Docker puede ocupar tan solo unas cuantas decenas de megas mientras que una máquina virtual, al tener que emular todo un sistema operativo, puede ocupar varios gigas de memoria. Lo cual representa un primer punto en el ahorro de coste.
Habitualmente cada aplicación en Docker va en su propio contenedor totalmente aislado, mientras que en las VMs es habitual debido al dimensionamiento tener varias aplicaciones en la misma máquina con sus propias dependencias, mucho peor para escalar de forma horizontal.
Básicamente, los contenedores se basan en dos mecanismos para aislar procesos en un mismo sistema operativo. El primero de ellos, se trata de los namespace que provee Linux, lo que permite que cada proceso solamente sea capaz de ver su propio sistema “virtual” (ficheros, procesos, interfaces de red, hostname o lo que sea). El segundo concepto son los CGroups, por el cual somos capaces de limitar los recursos que puede consumir (CPU, memoria, ancho de banda, etc)
De aplicaciones monolíticas a microservicios
Antes de pasar a hablar de Kubernetes como otro de los actores importantes de cómo ha cambiado la forma de desarrollar y escalar aplicaciones, vamos a analizar la evolución de esas arquitecturas en estos últimos años.
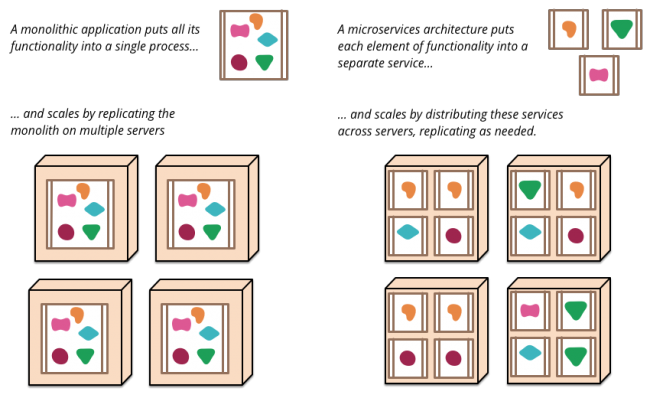
La definición clásica de una aplicación monolítica se refiere a un conjunto de componentes acoplados totalmente y que tienen que ser desarrollados, desplegados y gestionados como una única entidad. Prácticamente encajonados en un mismo proceso muy difícil de escalar, solo de forma vertical añadiendo más CPU, memoria. A todo esto hay que añadir el hecho de que para desarrollar un programador necesita tener todo ese código y ejecutar las pruebas levantando un única instancia con todo, a pesar de que el cambio que quiera realizar sea mínimo. Sin hablar de lo costoso que se convierte cada vez que se quiera hacer una nueva release tanto en desarrollo, pruebas como despliegue.
En contraposición a esto, surgió el concepto de microservicios que permite que varias pequeñas aplicaciones se comunican entre sí para ofrecer una funcionalidad específica concreta.
Tenemos el caso de Netflix, por ejemplo, una de las compañías que comenzó a hacer uso de forma más intensiva de los microservicios: Aunque no tenemos un cifra concreta, podemos estimar según los datos de muchas de sus charlas técnicas que cuenta con más de 700 microservicios.
En un ejemplo podemos hablar de un contenedor con un microservicio que se encargue de servir el vídeo según la plataforma desde donde accedemos, ya sea móvil, smart tv o tablet. También podríamos tener otro que se encargue del historial de contenido que hayamos visto, otro para las recomendaciones y, por último, otro para el pago de la suscripción.

Todos ellos pueden convivir en la nube de microservicios de Netflix y comunicarse entre sí. No necesitamos modificarlos todos a la vez, ya que podemos escalar algunos de los contenedores que tenga alguno de los microservicios y ser reemplazados prácticamente al vuelo.
Después de esto podemos ver de una forma más clara como todos estos microservicios han ido adoptando la forma de contenedores de dockerizados comunicándose entre sí a través de nuestro sistema.
Kubernetes: la necesidad de tener un maestro de orquesta
Si el número de aplicaciones crece en nuestro sistema, se convierte en complicado de gestionar. Docker no es suficiente, ya que necesitamos una coordinación para hacer el despliegue, la supervisión de servicios, el reemplazo, el escalado automático y, en definitiva, la administración de los distintos servicios que componen nuestra arquitectura distribuida.
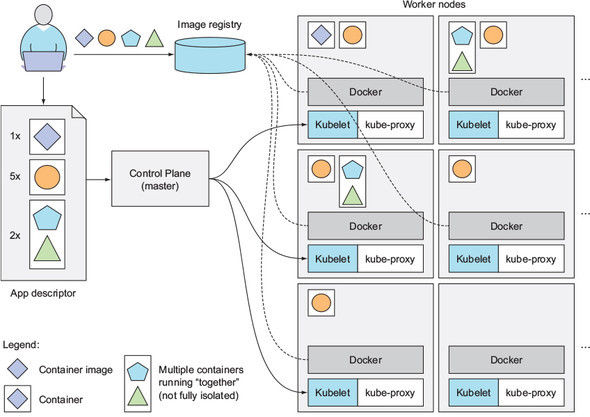
Google es probablemente la primera compañía que se dio cuenta de que necesitaba una mejor forma de implementar y administrar sus componentes software para escalar a nivel mundial. Durante años, Google desarrolló internamente Borg (más tarde llamado Omega).
En 2014, después de casi una década de uso intensivo interno, se presentó de forma pública Kubernetes como un sistema Open Source basado en el aprendizaje utilizando servicios a gran escala.
Fue en el la DockerCon de 2014 cuando Eric Brewer, VP de Engineering, lo presentó bromeando como que era otra plataforma de orquestación más. De hecho, en la DockerCon de 2014 se presentaron una decena de sistemas similares, algunos públicos y otros internos como Facebook o Spotify. Finalmente, después de cinco años, el proyecto sigue avanzando a toda velocidad, y hoy, Kubernetes es el estándar de facto para implementar y desplegar aplicaciones distribuidas.
Lo más importante es que Kubernetes fue diseñado para utilizarse en cualquier lugar, de modo que puede orquestar despliegues in situ, en nubes públicas y en despliegues híbridos.
El futuro de los contenedores
La adopción en el uso de contenedores continuará creciendo. También estamos viendo cierta estandarización en torno a Kubernetes y Docker. Esto impulsará el crecimiento de un gran número herramientas de desarrollo relacionadas.
El stack tecnológico empieza a madurar bastante y casi todos los proveedores empiezan a ser compatibles entre sí gracias a Docker y Kubernetes. Google, Microsoft, Amazon o IBM, por ejemplo, ya lo son y trabajan bajo un mismo estándar. La lucha ahora se encuentra en mover toda esa carga de trabajo que aún no está en la nube: la nube híbrida.

Quedan retos pendientes como seguir simplificando la curva de aprendizaje, aunque ya se ha mejorado bastante si echamos la vista a los últimos cinco años. A pesar de ello, los desarrolladores necesitan todavía aprender cómo producir una imagen de Docker, cómo implementarla en un sistema de orquestación, cómo configurarla y más detalles de seguridad. Algo nada trivial al principio. Estamos seguros de que en poco tiempo veremos cómo eso se simplifica aún más, ya que los desarrolladores trabajarán sobre niveles de abstracción superiores, gracias al ecosistema creciente en torno a Docker y Kubernetes.



Comentarios